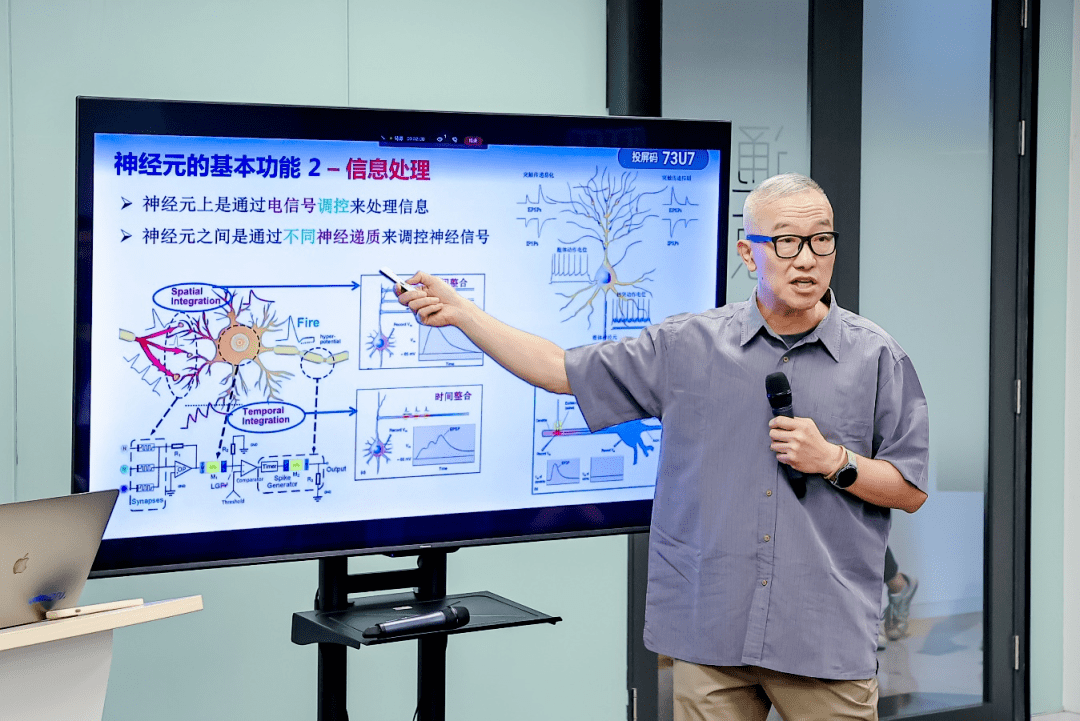
当图像放大到网络模式时,希恩斯看到了无数神经信号沿着纤细的突触忙碌地传递着,像错综管网里流淌着的闪光珍珠…… “这是谁的大脑?”希恩斯在惊叹中问道。 “我的。”山杉惠子含情脉脉地看着丈夫,“出现这幅思维图景时,我正在想你。” ――《三体 II:黑暗森林》 前几天,蚂蚁技术研究院和复旦大学脑科学研究院宣布他们联合攻坚的类脑研究――“基于图计算的脑仿真架构”校企合作项目正式启动,目标是打造新一代大规模高精度脑仿真系统,而我们离这一科幻场景和大刘“理工科的浪漫”又近了一步。 带着加深对生物智能的理解,以及为脑疾病治疗提供新的研究手段的目的,这个项目集结了图计算和实验神经科学等尖端学科,是一件极富想象力却也挑战重重的事情,就像是试图用一个非常复杂的东西来解释另一个非常复杂的东西,为什么要这么做呢?蚂蚁技术研究院院长陈文光认为,“两者之间的逻辑关系是互为手段,互为目的”,而这句话仿佛一个注脚,以比“人工”智能、“电”脑等名词更直接的方式,诠释了计算机科学与神经科学之间跨越几十年、千丝万缕的互生关系。
认识你自己 时至今日,刻在希腊德尔斐神庙门楣上的这句箴言,不论从哲学上还是生理上都接近一个不可能解决的问题。 自从现代人体解剖学之父安德烈亚斯・维萨里斯在 16 世纪首次将手术刀伸向人体,人类开启了向内探索之路。多年来我们了解了器官、组织,理解了消化系统、循环系统甚至外围神经系统,却始终对大脑――这一宇宙间最复杂的物体知之甚少,而它才是认识自我、理解意识和智能的关键。人类大脑重约 1.4kg,仅占体重的 2~3%,却包含了 860 亿神经元、比神经元高四个数量级以上的突触,仅已知能够呈现出的状态就有 2000 万亿种,而“作为我们与物理世界交互的真正工具,其能耗才不到 30W,且一生之中没有任何备件可供更换”,领衔项目的复旦大学脑科学研究院高级 PI、博士生导师王云讲述道。
理解大脑能够帮助我们提升人类的学习和记忆能力、应对脑相关的疾病,乃至理解智能,科学家们也从未停止对大脑的探索。那么迄今为止,我们干得怎么样?有人乐观地相信,人类已经理解了大脑的 40%,也有人悲观地认为这个比例仅有不到 1%,而研究了 40 年脑子的王云则略为无奈地表示,“我不知道”。可以说,碍于显微技术的局限,以及当前实验神经科学低通量的研究方式,对人类而言,大脑仍像一个神秘的“黑盒”,以不为人知的方式运转着。 为了解决这个问题,“从有计算机开始,搞计算机的人就思考着、尝试着用它做大脑仿真,弄明白大脑”。事实上,计算机科学与神经科学催生的计算神经科学由来已久,最早的神经系统仿真可以追溯到上世纪 50 年代。1952 年纯物理的霍奇金-赫胥黎模型(HH Model)被发表,而没过多久,到 1965~1975 年人工智能促进协会(AAAI)的科学家们建立的人工神经元网络(ANN),再到 1985~1995 年间日本生物计算机发展的十年,计算机科学在不断进步;另一方面,上世纪 70 年代膜片钳技术的发明,使得记录单个离子通道的电流成为了可能,为神经元电生理模型的建立打下了基础,发明者厄文・内尔和伯特・萨克曼也因此获得 1991 年的诺贝尔生理学或医学奖。 千禧年之后,深度学习的出现使得计算机、人工智能技术飞速发展,最初受到生物神经网络启发而建立的人工神经网络深度愈发加大,各种模型相继出现,终于催生了基于注意力机制的 Transformer 和我们现在所熟知的 GPT-4,Google Bard,Claude 等大型语言模型(LLM)。然而,其庞大的数据量、神经网络的深度和亿万级别的参数量,使得开发它们的科学家也无法解释乃至预测这些大模型的行为。当下,人工智能三巨头之一的 Yann LeCun 认为大模型并非通往通用人工智能的正途,而另一巨头 Geoffrey Hinton 则相信它们的学习方式强于人类,双方各执一词、争论不下,不过一个明显的事实是,大模型的工作方式已与人类智能相去甚远。讽刺的是,我们”仿生“多年创造出来的 AI 成为了另一个无法理解、不可解释的“黑盒”,神秘、强大,却无法帮助我们更好地理解人类大脑了。
凡我不能创造的,我就尚未理解 不过,一切努力并没有白费。得益于神经科学技术和计算机技术的长足进步,人类仍在寻求新的方法研究大脑这一世界性的难题。随着算力的不断提升和多通道膜片钳技术的出现,世界各国相继出台自己的“脑计划”,包括 2013 年启动的美国“脑科学计划”(BRAIN Initiative),同年启动的欧洲“人脑计划”(HBP)等,不过两者的思路并不相同。BRAIN 致力于绘制最完整的人脑细胞图谱,侧重于生物实验的测量和记录;HBP 则试图在十年内用超级计算机模拟人脑的全部神经元和它们之间的一百万亿个连接,更偏向于计算模型的建立,这一宏伟的计划也因其“野心过大”而遭到许多业界专家的非议。而 2021 年正式启动的“中国脑计划”则介于两者之间,“一体两翼”,既做脑科学基础理论研究,也做类脑研究,也就是计算神经科学的一部分。 虽然有着各种各样的局限性,但所有这些前沿科研的工作以及计算机科学的发展无疑为更先进的图计算脑仿真方法带来了宝贵的积累。神经科学的进步与各国脑计划的进展,提供了丰富度前所未有的大脑数据集,是一切研究的源头;算力的指数级提升和模型算法的不断优化,给了大脑数字孪生一个实现的可能性;显微技术的发展使得我们的观察精度达到了 10 的-10 次方,能看见原子,从而更好地理解神经电信号的传导和处理;同时脑疾病的蔓延和对个性化医疗需求的增长,也在客观上驱动了创新研究方法的发展。“历史是螺旋上升的,而现在时候到了。”复旦大学脑科学研究院工程师王小斐这样说道。 那么,为什么是图计算呢?要回答这个问题,我们首先需要了解一下什么是图计算。 从本质上来说,图计算呈现的是一种抽象的数据结构,由顶点和边两种数据类型组成,擅长表达事物及其相互之间的关联关系,而相对于关系型数据来说,图数据更直观、更符合人类的认知习惯,且在路径查找、复杂关系解析、群体特征提取等方面大幅优于需要穷举的关系型数据,能够高效地将多个数据来源整合在一张关系网络上。
听起来是不是很像我们大脑的神经网络?没错,图计算的模式与神经元、脑仿真有着天然的相似性,前者更像是后者的一种自然抽象。相对于和生物神经网络分道扬镳的大模型深度神经网络,图数据中顶点之间的连接更为“稀疏”,与主流深度神经网络中每一层神经元全部彼此相连的“稠密”连接截然不同,更接近于大脑的神经网络;同时,图计算的特性也决定了其参数和途径的透明和可解释性,从“黑盒”变成“白盒”;而最重要的是,图数据中边的建立和神经元突触生长的逻辑极为相似,为脑仿真模型带来了前所未有的动态性,也让我们离破解这一电生理现象之谜更近了一步。
同时,当前脑仿真系统的常用架构开发可追溯到上世纪 90 年代,可以说是立足于 20 年前的数据量、计算能力和生物学对神经的理解,虽然技术成熟度很高,但其更关注单个神经元细胞的模拟而非整个神经网络,采用的也往往是传统的多进程并行计算架构,在如今看来已经颇为过时。“现代的图计算引擎则是多进程与多线程混合并行的模式”,蚂蚁技术研究院图计算实验室研究员朱晓伟解释道,能够容纳更大量的数据、提供更强的算力且能耗更低,更适用于构建整个大脑的精确仿真模型。 回到脑科学研究上。当前的技术下,仅仅是做针对五六对神经元的电生理信号记录,就需要一个专业研究团队两到三周的时间,而如果再针对某一病症进行病理分析的话,王云保守估计需要三到五年的时间。他的愿景,就是用图计算引擎构建一个高精度的、动态的仿真脑模型,通过虚拟研究和虚拟筛选的方式大大缩短这个时间。
拼出一个大脑 当然,要实现这样宏伟的目标,挑战是非常大的。据朱晓伟介绍,图计算往往面临着数据规模极大、幂律度数分布导致的负载均衡问题。不过,蚂蚁在这方面有着非常深的技术积累,其 TuGraph 图数据库多次登顶行业权威测评 LDBC 榜首,是当前世界纪录保持者;更直观地说,我们日常使用的支付宝其实就在底层使用了蚂蚁的图计算技术,能够在庞大的用户基数和数据规模上,实现精准的金融风控、黑灰产识别等等。 然而,更大的挑战还不在此。让顶尖的复旦大学脑科学研究院与实力雄厚的蚂蚁技术研究院聚在一起,真正的挑战在于两拨人的“语言都不一样”,陈文光如此说道,“(脑科学和计算机科学)两个领域连术语同步都很难。”
关于这两个学科之间的壁垒和鸿沟,王小斐举了个生动的例子来说明,”搞计算机的人有了什么成果,第一时间就会把论文发表到预印本平台 arXiv 上;而搞生物的人绝对不会看,因为没有经过同行评审,99.9%的概率是在浪费时间和精力”。 也正是因为实验科学与计算机科学这个巨大的差异,双方的合作更显得至关重要,而促成这次宝贵合作的正是有着计算机和神经科学跨界背景的王小斐。“这件事情的缘起是小斐有一天在清华门口约我喝咖啡,拿着一份脑科学的论文找我谈图计算”,陈文光笑笑说,而这杯咖啡,王小斐等了二十年。2003 年,还是清华计算机系研究生的王小斐有一天去上了神经生物学的课,非生物科班出身的他交出了一份关于如何将 CPU 和人脑连接在一起的论文,而当时的导师谢佐平教授给他的评价是,“计算机系每隔十年,就会来一个你这样的”,王小斐回忆道。这不仅是他个人理想主义的一种坚持,也是自上世纪 50 年代以来无数科学家的向往,“我们还可以再试试”,王小斐这么说着,“拼”起了这个团队。 两个不同团队的碰撞与合作,带来的自然是两个学科研究范式的交叉与融合。与欧美脑计划都不同,蚂蚁与复旦的合作采用的是“干湿实验结合的研发方法”,一边基于图计算去构建动态、实时、高精度的脑仿真模型,搭建硅基空间的虚拟实验平台;一边基于实验神经科学,在碳基空间中对大脑真实数据进行测量和验证。“希望我们两个团队能够密切地结合在一起,得到的实验数据可以输入给图计算团队,帮助构建这个神经计算系统;而系统模拟得出的数据,又可以回到脑科学团队,在实验中得到验证”,王云如此说道。 蚂蚁和复旦团队的终极愿景当然是建立全脑的仿真模型。不过目前,他们第一期的目标是先构建出小鼠 MS 中脑间隔这个脑区的模型,瞄准的是与其密切相关的阿尔兹海默症这一至今无解的神经退行性疾病,项目周期为三年。如果模型验证成功的话,王小斐透露他们考虑将架构开源,为世界各地的脑仿真研究人员提供一个真正好用的开放性基础架构,并在上面分别搭建不同脑区的模型。“我希望全球人民帮我拼出一个脑子”,王小斐半开玩笑地说。 |
|
标题 >> |
他们正在尝试用“图”拼出人类大脑 |